Software
Engineer
I design and build complex, scalable systems — from backend architecture to AI-powered products.



Hi, I'm Luna — Chetan's AI assistant. Want to know more about him? Ask me below!

About Me
"The best way to predict the future is to invent it."
— Alan Kay
Hi, I'm Chetan — a software engineer specializing in designing and building complex, scalable systems. From backend microservices to AI-driven products, I love turning ideas into robust, production-ready solutions. Want to know more? Ask my custom-built AI assistant, Luna.
AI Assistant
Meet Luna
Built by Chetan — ask her anything about me
Luna
Chetan's AI Assistant
Career
Work Experience
Karela Technologies Inc.
Arizona, United States
Jan 2025 — Present
Chief Technology Officer
As CTO and co-founder, I lead the company's technical vision and innovation, overseeing the development of cutting-edge solutions. I manage a team of engineers, driving strategic decisions and ensuring successful execution of technology initiatives.
Lecturely AI
Arizona, United States
Aug 2024 — Mar 2025
Co-Founder / Founding Engineer (Backend & AI)
Built fault-tolerant microservices powering multi-agent workflows using Node.js, RabbitMQ, and Docker.
- • System design and architecture
- • RESTful and event-driven APIs in Node.js
- • AI agent development with OpenAI API
- • RabbitMQ for inter-service messaging
- • Docker containerization & AWS EKS deployment
TicketSewa Pvt. Ltd.
Pokhara, Nepal
May 2023 — Jun 2024
Co-founder & Software Engineer
Co-founded TicketSewa, an online ticketing platform. Architected a microservices-based system leveraging Redis for caching and AWS for containerized deployment.
- • System design and microservices architecture
- • RESTful and event-driven APIs in Node.js
- • Cross-team project management
Publications
Research
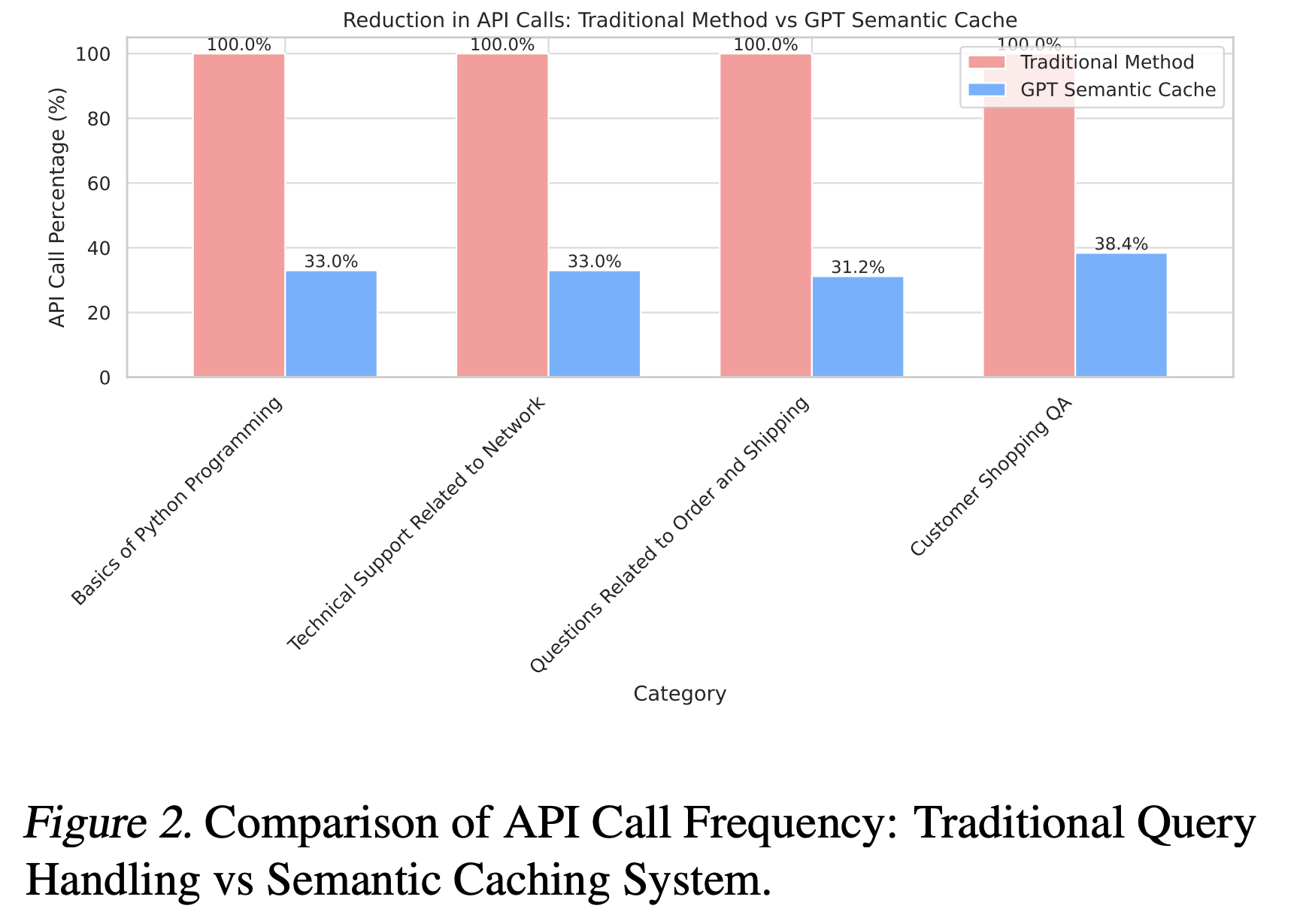
GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching
This research introduces GPT Semantic Cache, a method designed to optimize the efficiency of LLM-powered applications. It reduces computational costs and latency by caching semantic embeddings of user queries, enabling faster and more cost-effective responses for semantically similar queries.
68.8%
API Call Reduction
97%+
Positive Hit Rate
Portfolio
Featured Projects
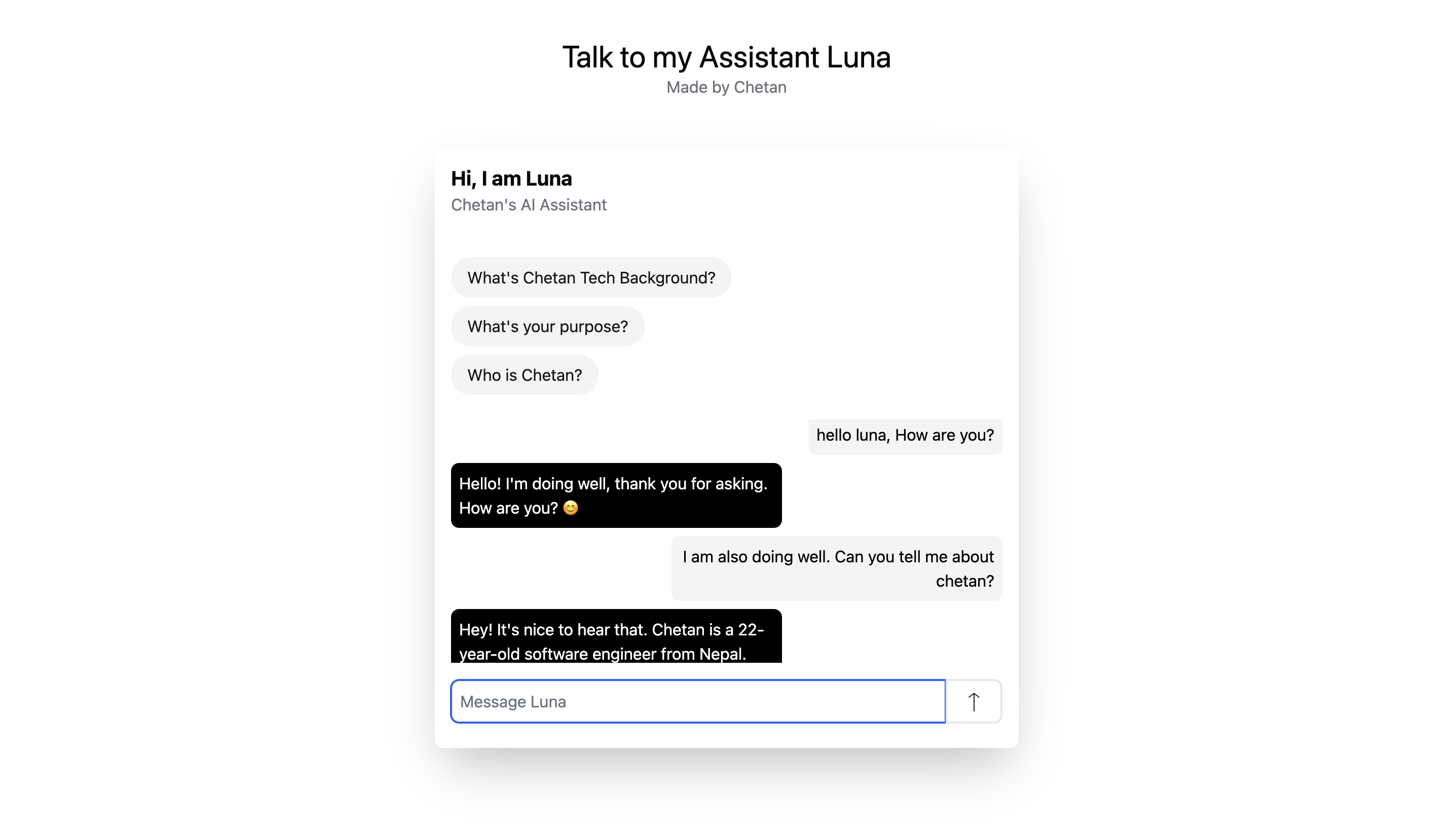
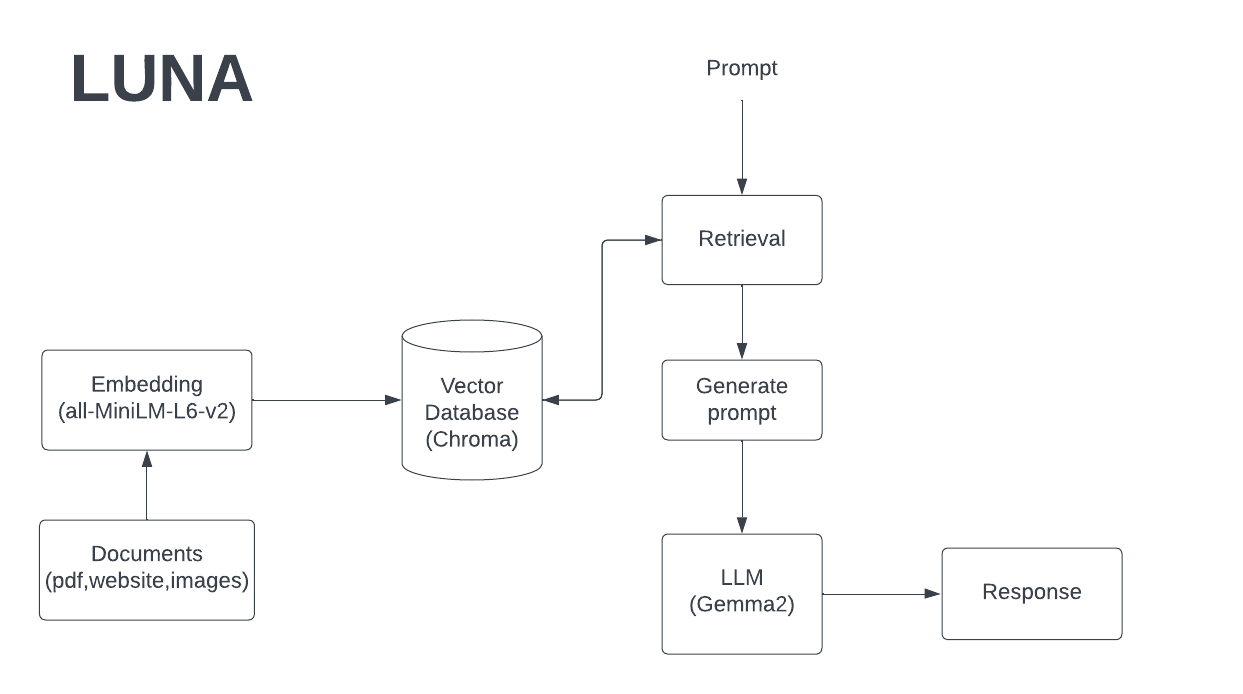
Luna
An AI assistant built on GPT-3.5 Turbo that uses RAG (Retrieval-Augmented Generation) to answer questions about Chetan. Luna improves with every conversation.
View Details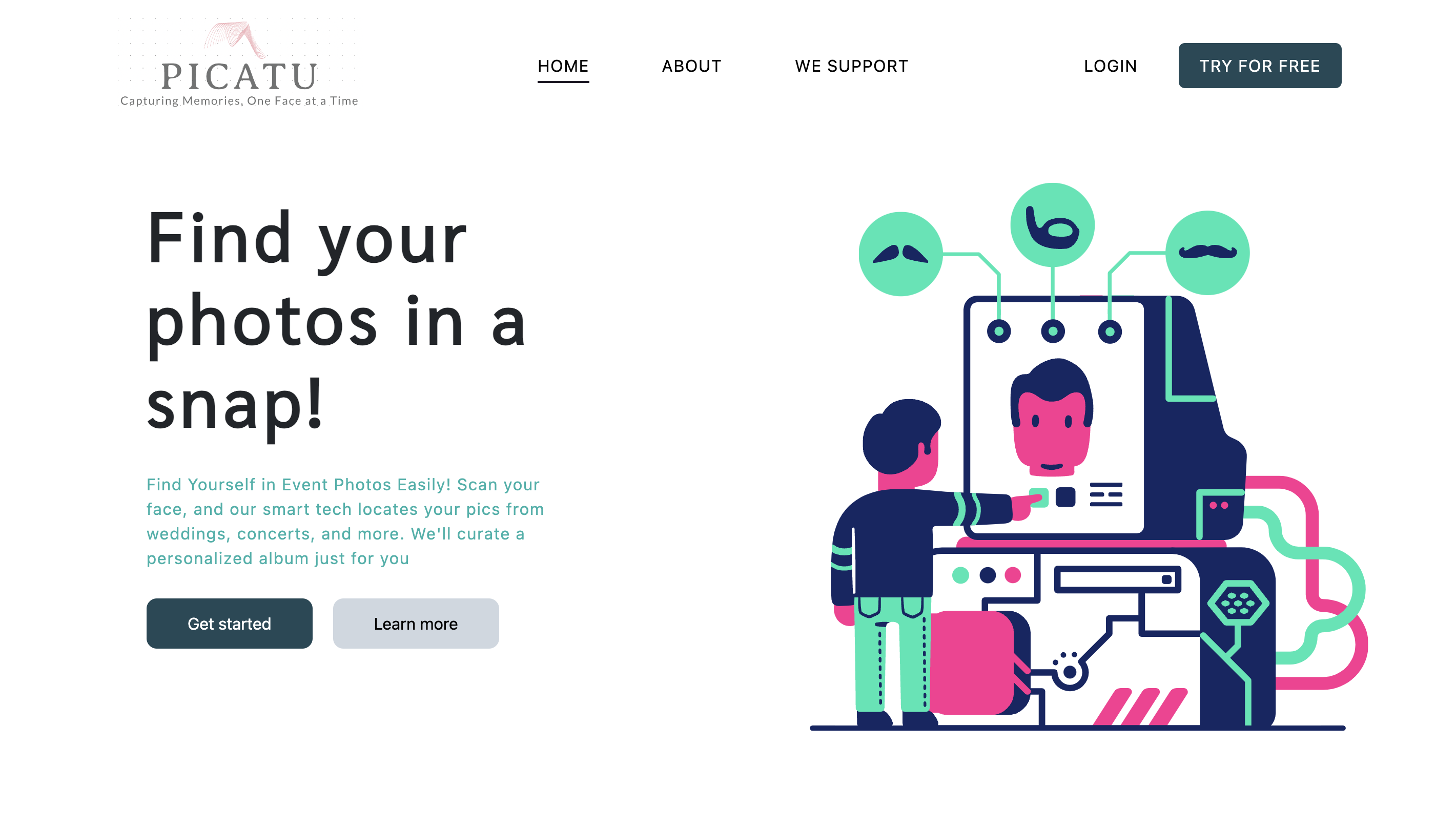
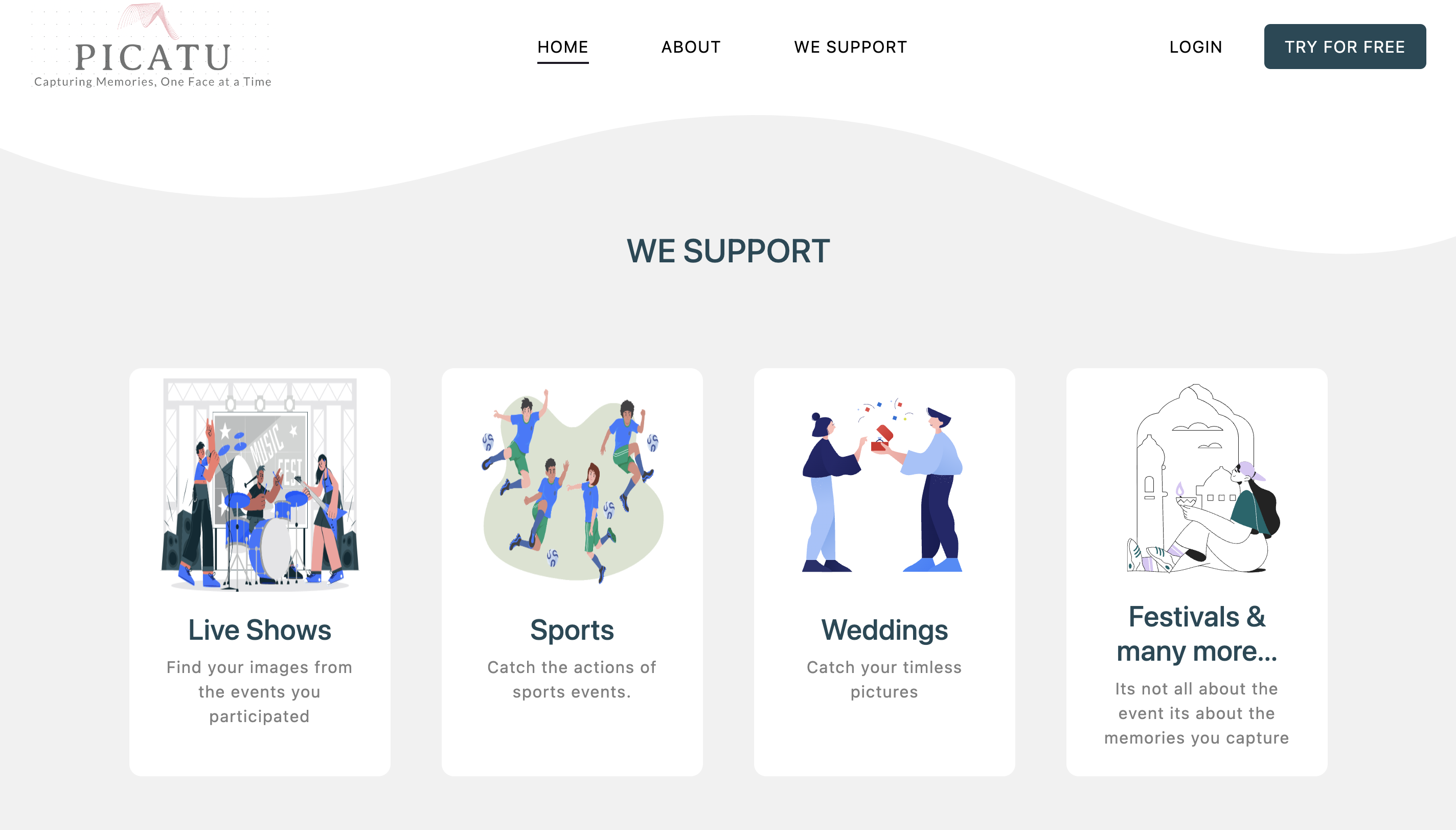
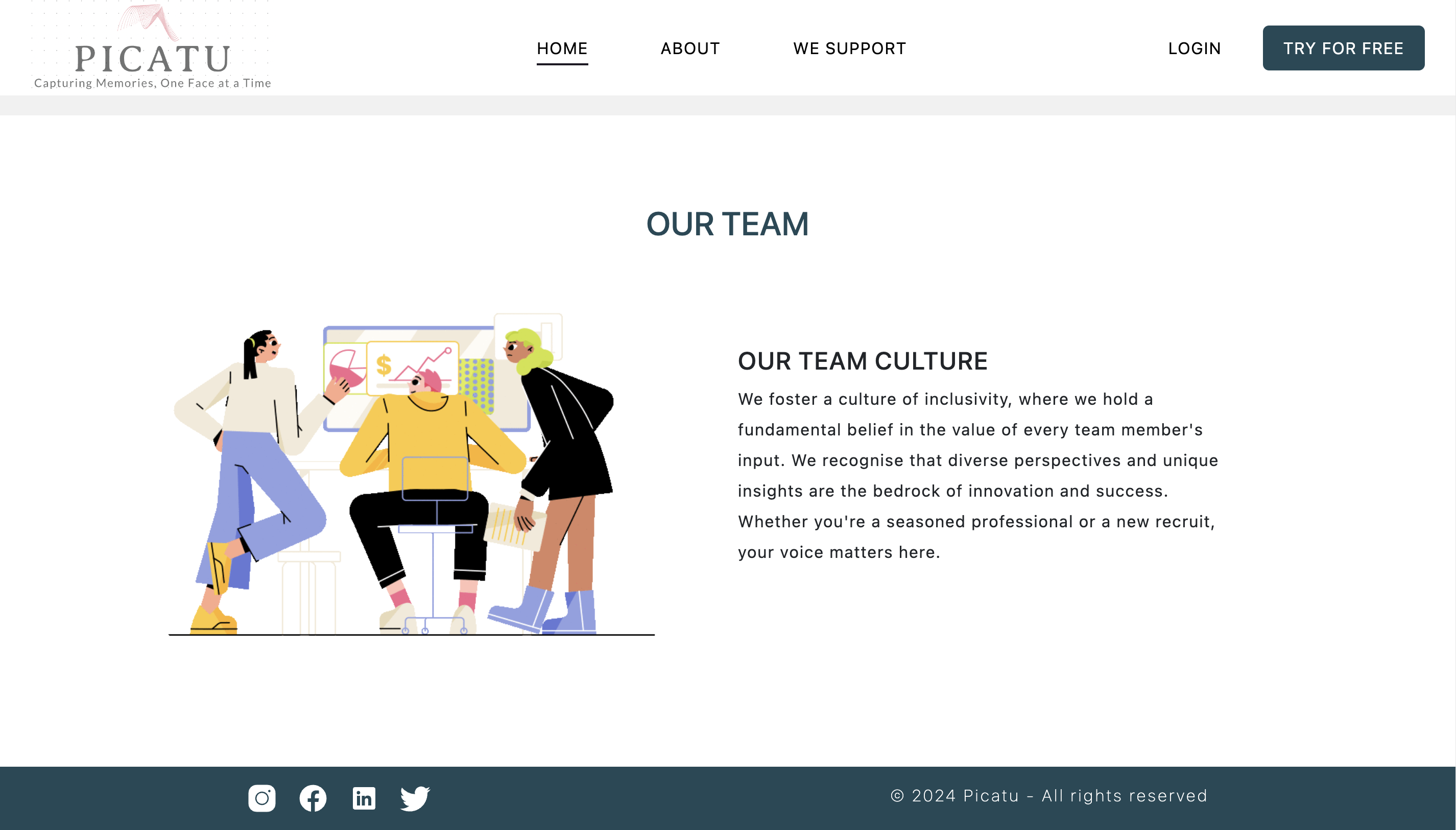
Picatu
A facial recognition tool that searches for images of specific individuals across event databases. Users input an image, and the system returns matches using a deep learning model.
View Details
Trusted Doctors
A web application connecting users with healthcare professionals, enabling seamless communication and access to quality healthcare services.
View Details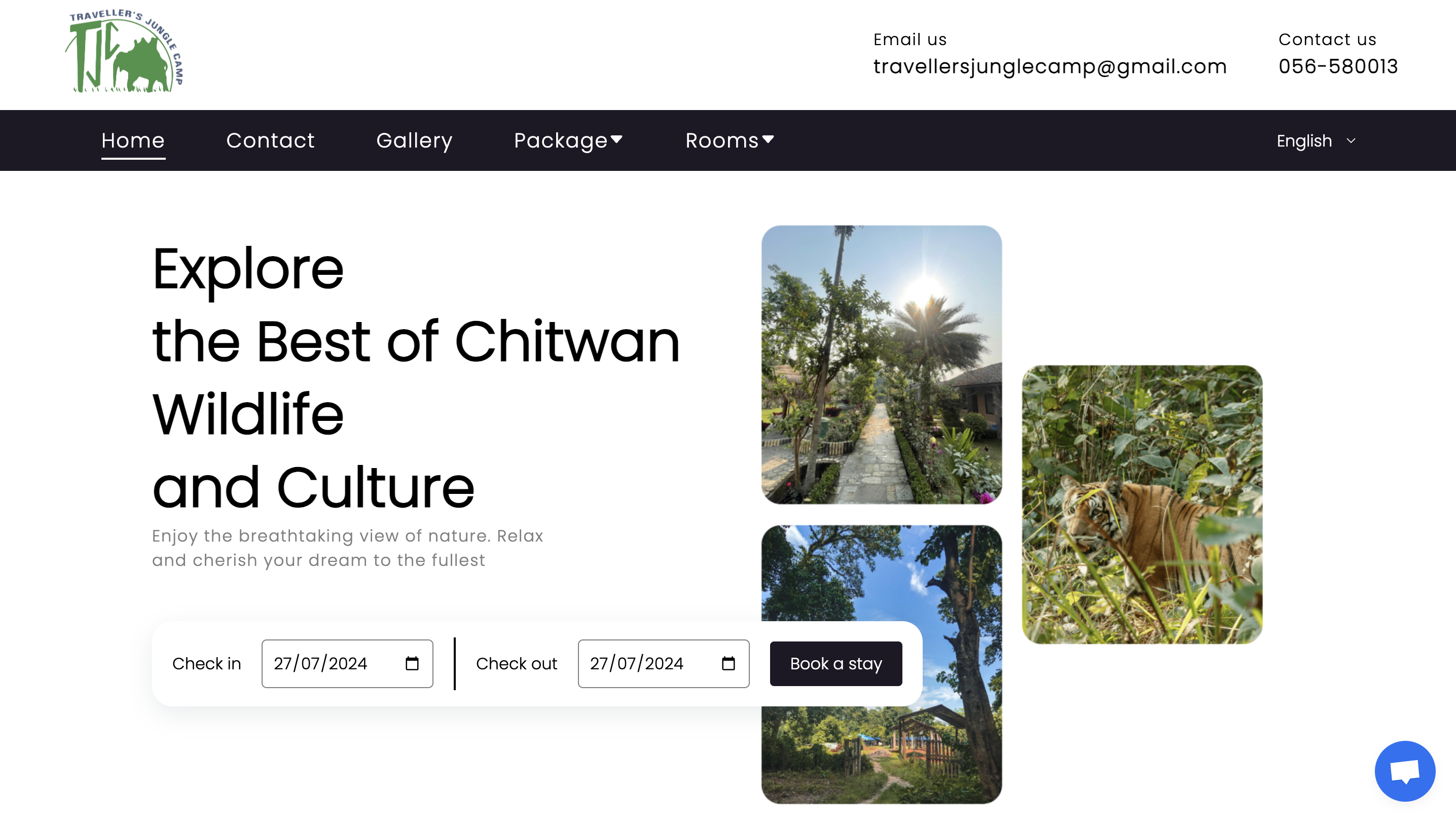
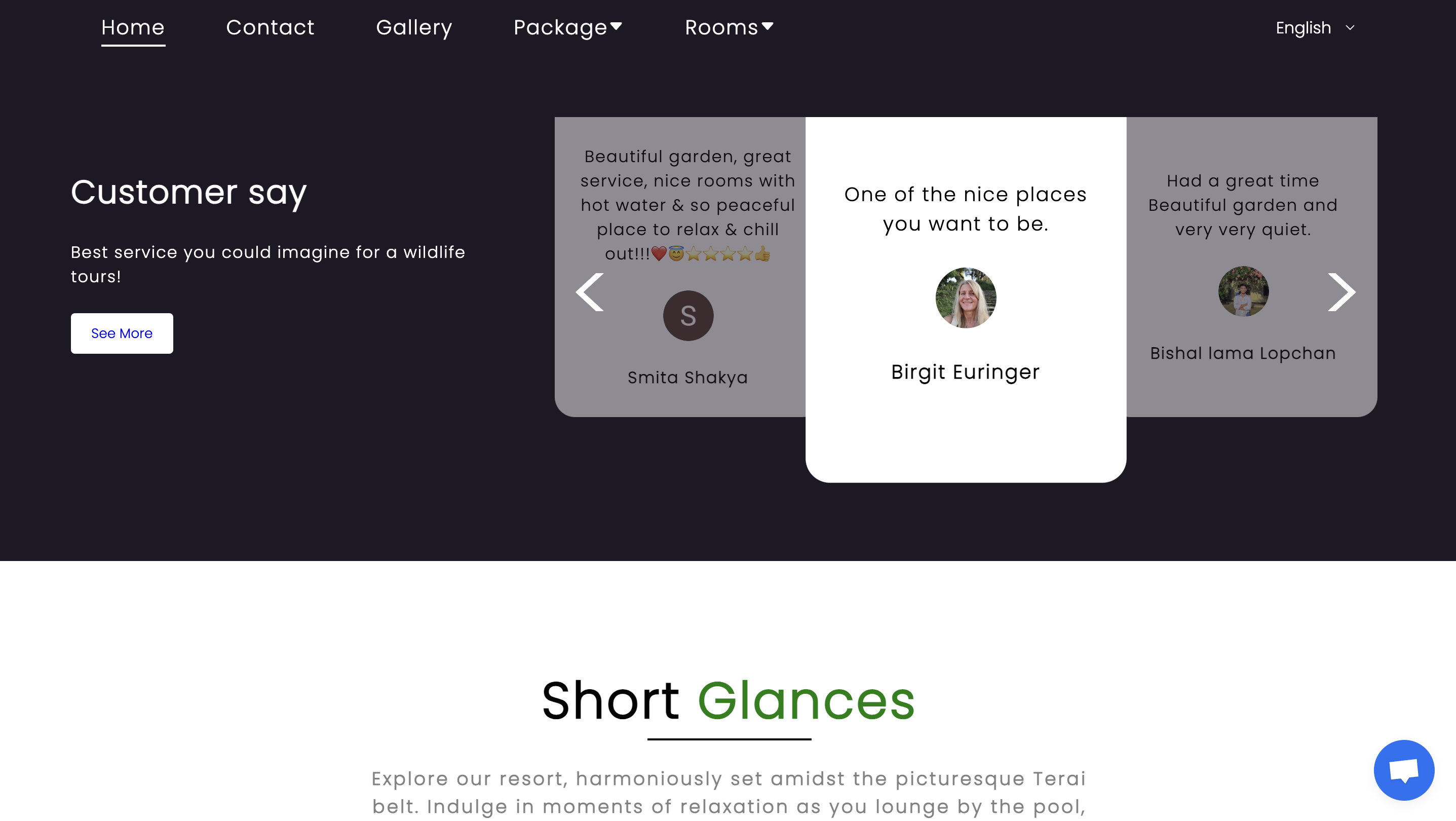
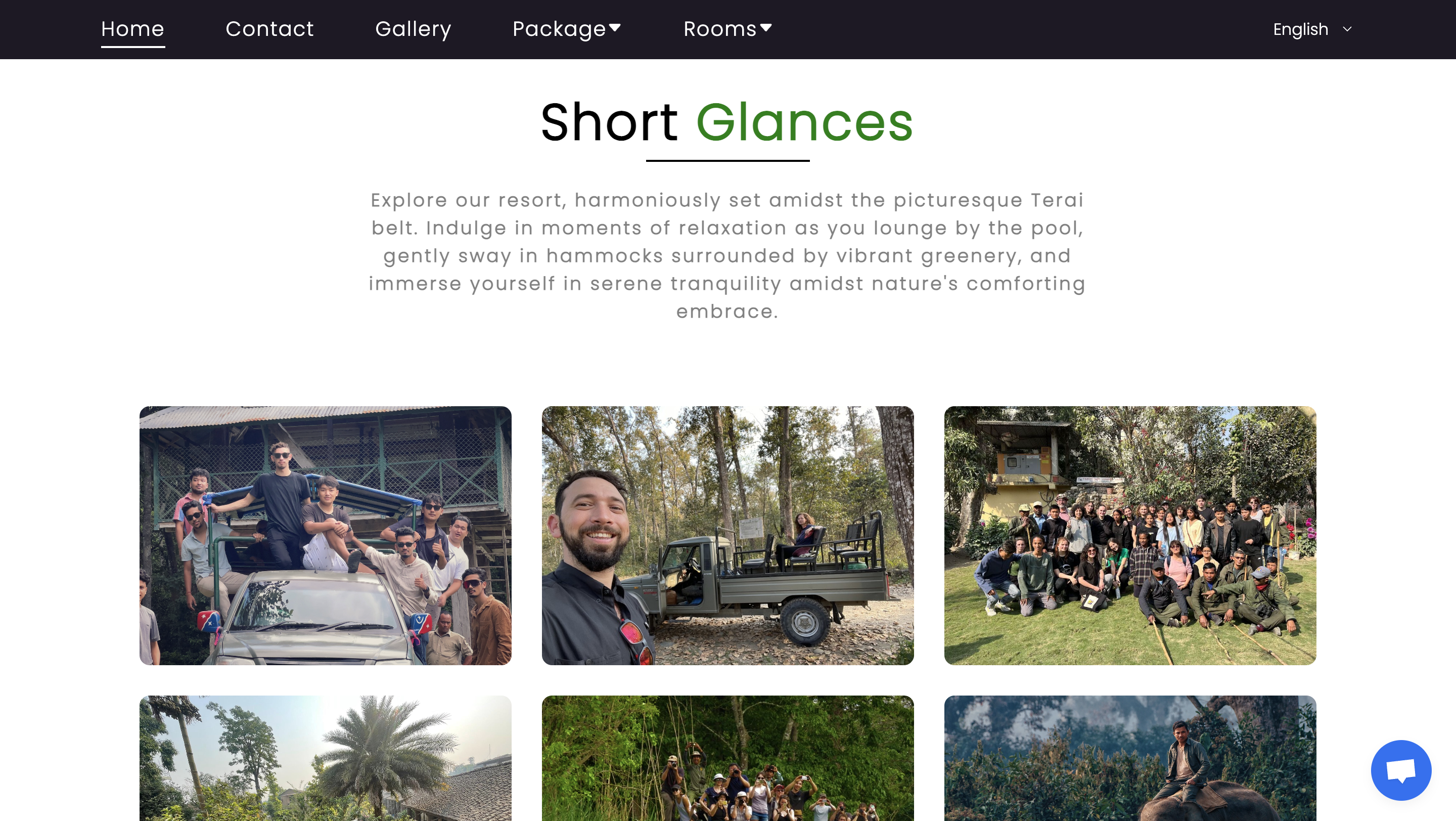
Travellers Jungle Camp
A resort website for Chitwan's Travellers Jungle Camp where customers can book rooms, jungle safaris, and more.
View DetailsGet in Touch
Let's Work Together
Have a project, question, or just want to say hi? Drop me a message.